Centrality Application: What affects Diffusion?¶
First contact points: let us examine how network positions of injection
points matter
Banerjee, Chandrasekhar, Duflo, Jackson, Diffusion of Microfinance (2012)¶
75 rural villages in Karnataka, relatively isolated from microfinance initially
BSS entered 43 of them and offered microfinance
We surveyed villages before entry, observed network structure and various demographics
Tracked microfinance participation over time
Background: 75 Indian Villages - Networks¶
"Favor" Networks:
- both borrow and lend money
- both borrow and lend kero-rice
"Social" Networks:
- both visit come and go
- friends (talk together most)
Others (temple, medical help...)



Data also include¶
Microfinance participation by individual, time
Number of households and their composition
Demogratphics: age, gender, subcaste, religion, professfion, education level, family...
Wealther variables: latrine, number rooms, roof
Self Help Group participation rate, ration card, voting
Caste: village fraction of "higher castes" (GM/FC and OBC, remainder are SC/ST)
Degree Centrality¶
- Count how many links a node has
- node 7 and 6 would be the most central individuals in the village, and if you hit those individuals, you would expect to reach more just because they have higher degree.

Hypothesis¶
In villages where first contacted people have more connections, there should be a better spread of information about microfinance
more people knowing should lead to higher participation

So it doesn't appear as if degree centrality really captures what's going on. So we need another centrality

Let's have a look at Eigenvector centrality, we realized that looking at degree doesn't tell a lot of the story because it doesn't capture how well you are positioned in a network. And so if we look at Eigenvector Centrality, where we have the centrality being proportional to the sum of the centralities of your neighbors, then we are getting something which reflects this better connectedness, as we talked about in the last lecture. Okay, so let's have a fiat and look and see if Eigenvector centrality does a better job.
Eigenvector Centrality¶
- If centrality is proportional to the sum of neighbors' centralities, then we're defining eigenvector centrality. So:
$C_i$ proportional to $\sum_{j:friend.of.i}C_j$
$C_i = a\sum_j g_{ij}C_j$
- $g_{ij} = 1$, then $c_j$ being counted
- $g_{ij} = 0$, then $c_j$ not counted
- we're just counting the centrality's of the friends you're connected to.
Basically what we have is that the vector C is equal to sum a times the matrix g times the vector C. And so this is what's known as an Eigenvector: $$C = agC$$

Hypothesis Revised¶
In villages where first contacted people have higher eigenvector centrality, there should be a better spread of information about microfinance
more people knowing should lead to higher participation
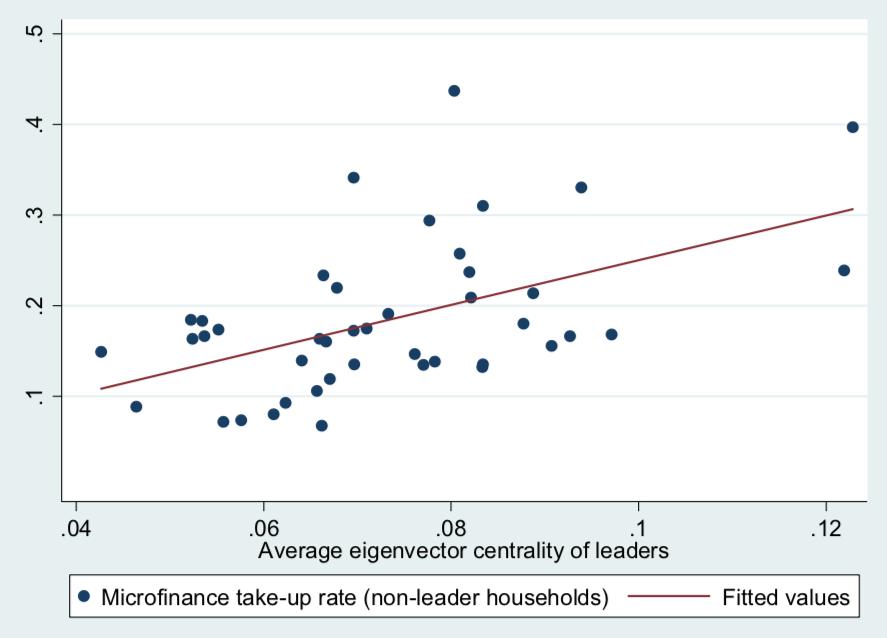
Now we get a significantly positive and strong relationship. So having better placed leaders in terms of eigenvector centrality does a reasonably good job of prediction the eventual mark microfinance participation, whereas the degree centrality didn't seem to pick things up.
the idea here is that, why's eigenvector centrality is working better? Because, you know this communication's a repeated process. You tell your friends. They have to tell their friends. And so forth. So if you have well-positioned friends, and they have well-positioned friends, that is good for diffusion. An eigenvector centrality is measuring that whereas degree centrality is not.
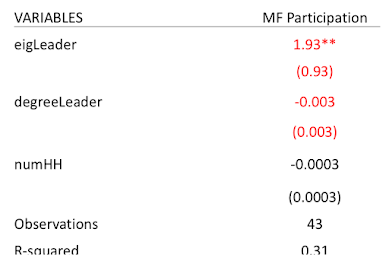
MF Participation: Regress micro finance participation on a series of variables
eigLeader: eigevectors of the leaders
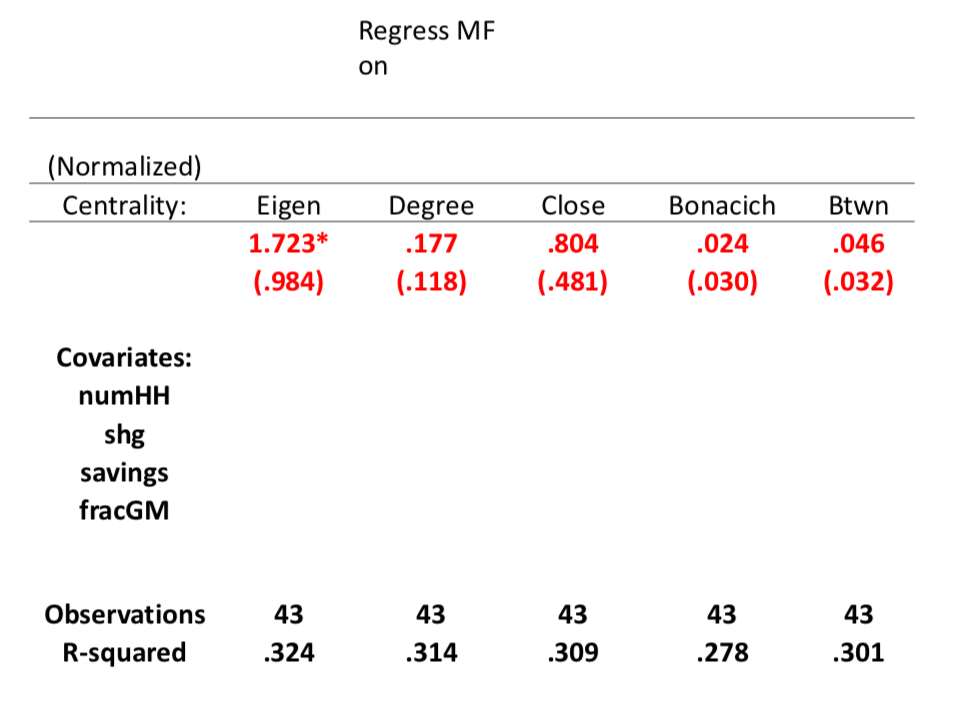
We are also correcting not only for the centrality, but also let's track of, you know some villages are going to be larger, so they might have larger numbers of people (numHH), some might have more people who participate in self help groups (shg), which means they're already more prone to be borrowing and lending from eachother. We have variables on savings (saving), we have caste variables (fracGM), we can look at a whole series of different variables and control those and see, you know, that takes some of things out.
And again, I can vector centrality, so now degree turns out to be positive and we control for these variables, but still insignificant compared to its standard area... Eigenvector centrality is the one which turns out to be positive and significant the other ones turn out not to be significant. So you know, this is just one application, but it's one application where now if we have a very particular question in mind and we look at which of the centrality measures correlates with the eventual outcome Eigenvector centrality is one that's correlating in a positive way and the other ones are not correlating significantly once we've controlled for a bunch of other variables.
So this just gives us an idea that these things are measuring different aspects of the network and sometimes one can be a better predictor than another. Now exactly what the causation here is we can tell stories, I can explain that it probably has to do with communication and better connected friends leads to better communication and so forth. Eigenvector centrality's picking that up. but, you know, this is observational data, so we're not sure what the causation is, but we do see that different. Measures or picking up different things in the data that's going to be important. Now again I want to emphasize here that this does not mean eigenvector centrality should be your only centrality measure. It just means in this particular application where we looking at a very specific type of diffusion it seemed to be a better correlator than these other standard measures of, of centrality, and depending on which application you're looking at, you know, between this seemed to do a little better at explaining what was going on possibly in the Florentine marriage data. So depending on which application you're looking at it might demand a different, centrality measure.