A Linear-Quadratic Model¶
Let's have a look at one other game with continuum of actions, so people can take a whole series of different actions, not just zero or one. And this is going to be one with compliments, strategic compliments, and it's a linear quadratic model, and so it's got a very simple structure to the payoffs which allows for a simple, closed form solution.
this comes out of a paper by Ballester Calvo-Armengol and Zenou in 2006
payoff: $u_i(x_i, x_{-i}) = a x_i - b x_i^2/2 + \sum_j w_{ij}x_ix_j$
strategic complements
the structure of the game, that the payoffs are very simple, and tractable. And so, in particular, when we think of a given individual taking their action, Xi. Other actions are taking, other people are taking actions X minus I, let's let xi be greater than or equal to zero, so I'm taking some real valued action. And the utility that people get, we can see why it's called linear quadratic, so, it's going to be increasing in my own action, just linearly. And quadratically, there's going to be a cost, so eventually I don't want to take too much action, because I'm going to pay for that in terms of Xi squared. but there's also the strategic complement aspect. So what I also do is I look at different friends, and I weight them, so I have some weight I on, on J. And what I get is some product of our actions. So, if other individuals are taking really high actions, then that gives me an incentive to take higher actions. I get a a payoff, a bonus, from taking higher actions when people take high actions, okay? So, the, the, the full model that they have allows also for some global substitutes, and so forth. But let's focus in on this essential aspect of the model. Which is the linear quadratic aspect. Which is that I get a positive payoff from my direct action. I get some negative cost and then which is quadratic, and then a bonus in terms of what other individuals are doing in, in a strategic confluence. Okay, so the nice thing about this is in this quadratic form it's going to be easy to figure out how, what's my best action given what other people are doing. And then to solve for nash equilibrium in this world is fairly easy. We'll be able to find a set of, of, of actions such that everybody is best responding to everybody else. We'll be able to solve that as a function of the network in a really clean and simple form.
Best response of $x_i$ to $x_{-i}$:
- $x_{-i}$ is the vector of the actions for everybody else besides i.
- if maximize the payoff equation with recpect to $x_i$, just take the derivative of this and set it equal to zero: $\frac{du_i}{dx_i}=0$
so : $a - b x_i + \sum_j w_{ij}x_j = 0$
$x_i = (a + \sum_j w_{ij}x_j)/b$
- So, the more activity your neighbors take the more you want to take, okay. And so you are getting benefits that are proportional to
a, and benefits proportional to how much action your neighbors are taking, and you pay a cost relative tob. And so we get this benefits in the numerator over the cost and that modulates exactly what they write $x_i$ is. so we've got a best response. What I should do in response to everybody else is. And then an equilibrium is going to be solving this set of equations simultaneously so everybody wants to be taking the action response to everybody else.
Thus vector equation is: $x = \alpha + gx$
- where $\alpha = (a/b, ..., a/b)$ and $g_{ij} = w_{ij}/b$
- $\begin{bmatrix} x_1 \\ \vdots \\ x_n \end{bmatrix}$ = $\begin{bmatrix} a/b \\ \vdots \\ a/b \end{bmatrix}$ + $\begin{bmatrix} w_1 + \cdots + w_j \\ \vdots \\ w_1 + \cdots + w_j \end{bmatrix}$ $\begin{bmatrix} x_1 \\ \vdots \\ x_n \end{bmatrix}$
Based on vector equation:
$x = \alpha + g(\alpha +g(\alpha + g...))) = \sum_{k \ge 0 }g^k\alpha$
or $(I-g)x = \alpha$ $\rightarrow$ $x = (1- g)^{-1}\alpha$
- if $(1- g)^{-1}$ invertible, then $\sum_{k \ge 0 }g^k\alpha$ is converge
or if a=0, then $x = gx$, so unit eigenvector
Actions are related to network structure
higher neighbors' actions, higher own action
higher own action, higher neighbors actions
feedback - for solution need b to be large and/or $w_{ij}$'s to be small
Relation to centrality measures:
- $x = \sum_{k \ge 0 }g^k\alpha$
- or $x = (1- g)^{-1}\alpha$
- recall Bonacich centrality: $B(g) = (I - g)^{-1}g1 = \sum_{k \ge 0} g^{k+1}1$. number of paths from i to j of length k+1, summed over all k+1, here weighted and directed $w_{ij}/b$
- So, $x = (1 + B(g))(a/b)$. So in fact what we can say is the action that any individual taken one of these linear quadratic games of complementarities is something which is proportional to their Bonacich centrality. So, higher Bonacich centrality, higher actions, okay. So we've got everybody takes an action, A over B to begin with, which is just sort of what they would in isolation with no network. And then the extra network effect adds in these complementarities. And how much extra action they get here depends on their Bonacich centrality in the network.
Natural feedback from complementarities, actions relate to the total feedback from various positions
Centrlity: relative number of weighted influences going from one node to another
Captures complementarities
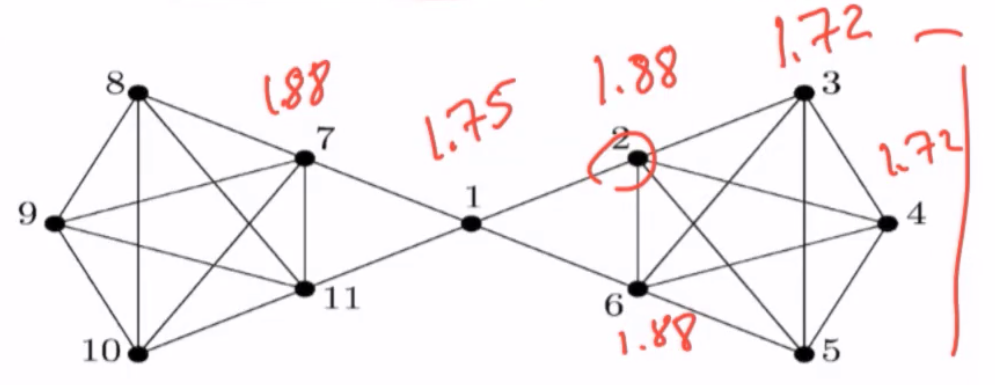
Example¶
$x = (1+B(g))(a/b)$
Scales with a/b, this scales with A over B so this is just multiplying everywhere so we can just rescale and ignore that
$g_{ij} = w_{ij}/b$, let us take $w_{ij}$ in {0,1} and then only b matters
B(g) = 1.75, 1.88, 1.72 for 1,2,3 if b = 10(relatively high cost to taking actions)
- = 8.33, 9.17, 7.88 for 1,2,3 if b = 5